- 03-5820-1777平日10:00〜18:00
- お問い合わせ
コラム
[AWS]データベース比較(RDS,DynamoDB,Redshift,ElastiCache)
AWSで使用可能なデータベースの簡単な比較をまとめてみました。
比較表
| サービス | RDS | DynamoDB | Redshift | ElastiCache (Redis) | ElastiCache (Memchached) |
|---|---|---|---|---|---|
| DBタイプ | リレーションナル型 | ワイドカラム型 | データウェアハウス型 | キーバリュー型 | キーバリュー型 |
| 作成場所 | AZ | リージョン | AZ | AZ | AZ |
| クロスリージョン | 〇 | 〇 | 〇 | 〇 | ✕ |
| バックアップ | 最短5分前 | 最短5分前 | 最短1分前 | 最短60分前 | ✕ |
| 永続化 | 〇 | 〇 | 〇 | 〇 | ✕ |
自動フェイルオーバー
| RDS | DynamoDB | Redshift | ElastiCache (Redis) | ElastiCache (Memchached) |
|---|---|---|---|---|
| 可能 | リージョン作成なので必要なし | 別AZに再配置する機能が存在する自動的にスレイブへの切り替え機能はない | クラスターモード有効の場合は可能 | 不可 |
スケーリング
- RDS
- リードレプリカ追加
- メモリ・CPU増強
- 自動化はストレージサイズのみ
- シャードするには別途ソフトウェアが必要、オンラインでのシャーディング対応は不可
- DynamoDB
- 自動スケーリングか拡大範囲を指定
- 拡大範囲はプロビジョンドキャパシティーユニットを指定
- Redshift
- ノードスペック変更
- ノード追加
- 同時実行スケーリングで一時的なクラスタ追加の自動化も可能
・ElastiCache
RDS
概要
フルマネージメント型のRDB機能を提供します。
主に業務システムなどで最も頻繁に利用されるオペレーション用のデータベースです。
複雑なクエリー処理をするにに向いています。
DBはMySqlやOracleなどの一般的なものが使用可能です。
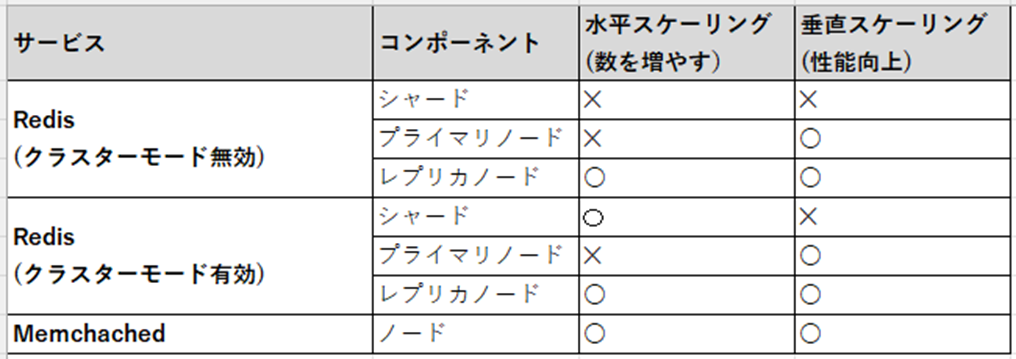
アーキテクチャ
データベースを作成し、その中にテーブルを複数作成する事が出来ます。
負荷分散や障害を起きた際の為、データベースを複数作成させて対応します。
障害用のスレーブRDS、読取り用のリードレプリカを作成する事が可能です。
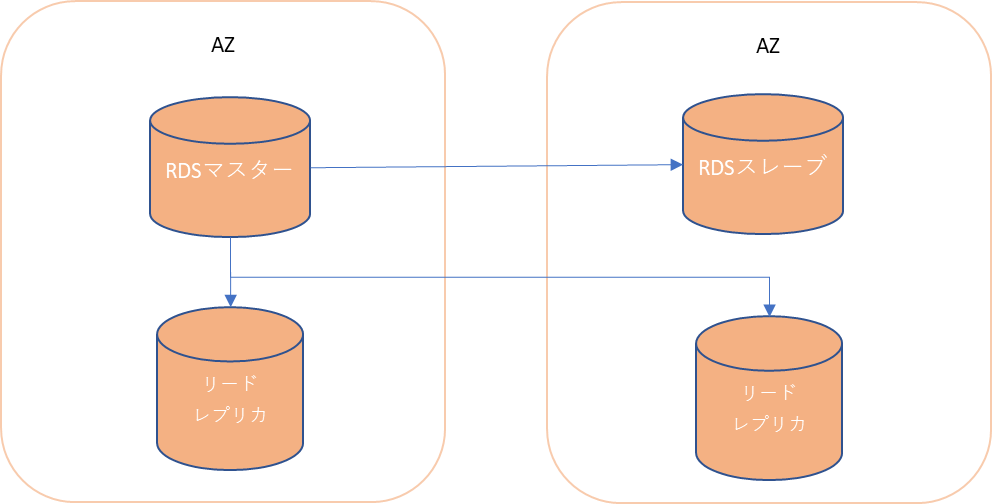
データ構造
テーブルを複数作成する事ができ、テーブル間のリレーションが定義されたデータモデル。
行を1つのデータのかたまりとして取り扱う。
データイメージ
データ例
| ユーザID | クエストID | 日付 | スコア | クリア人数 |
| 001 | 1 | 2022/1/1 | 10000 | |
| 001 | 2 | 2022/1/2 | 5000 | 2 |
| 002 | 1 | 2022/1/1 | 20000 |
使用例
- 業務データ
- テーブル間の関連が密接なデータ
- 会計データ
- 販売管理データ
DynamoDB
概要
シンプルなオペレーションを高速に実施できます。処理する際はデータをパーティションニングして分散処理をして高速化します。
可能な限り多くのデータを同じ行に保持し、複雑なクエリーを必要としない構造のデータを管理するのに向いています。
個人的には使い所が中々難しいDBだと思います。
ElastiCacheで使用するデータ構成でフルマネージメントかつ永続化したい時や、リクエスト件数が多大でRedisのクラスターでは対応できない時などに使用するのかな。。。
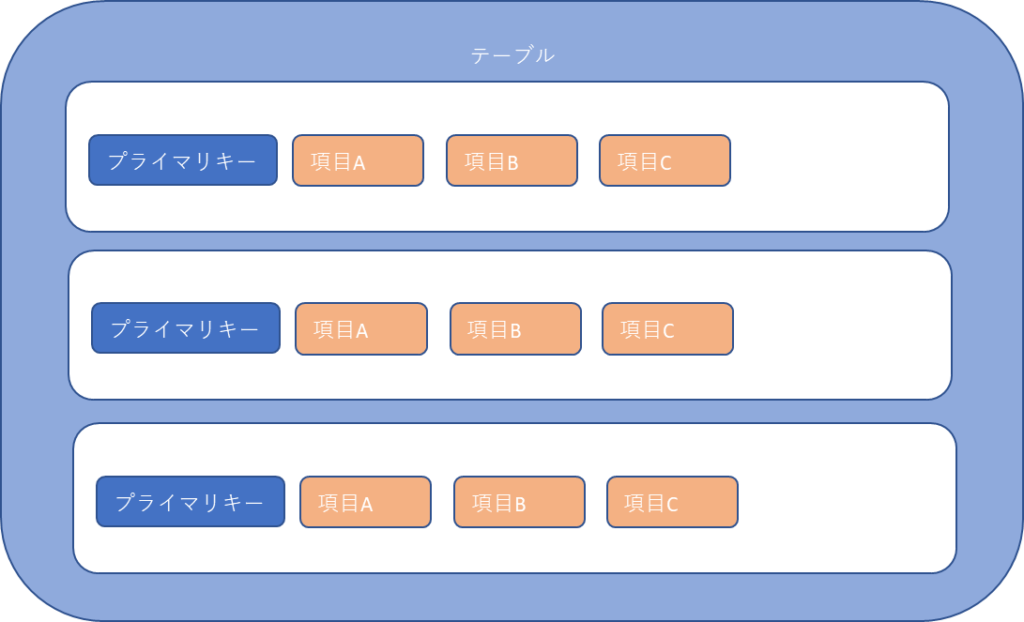
アーキテクチャ
テーブルを作成し、大量データを高速処理するためにパーティショニングによる分散処理を実施している。
データやリクエストに応じたスケーリングは自動的に実行してくれます。
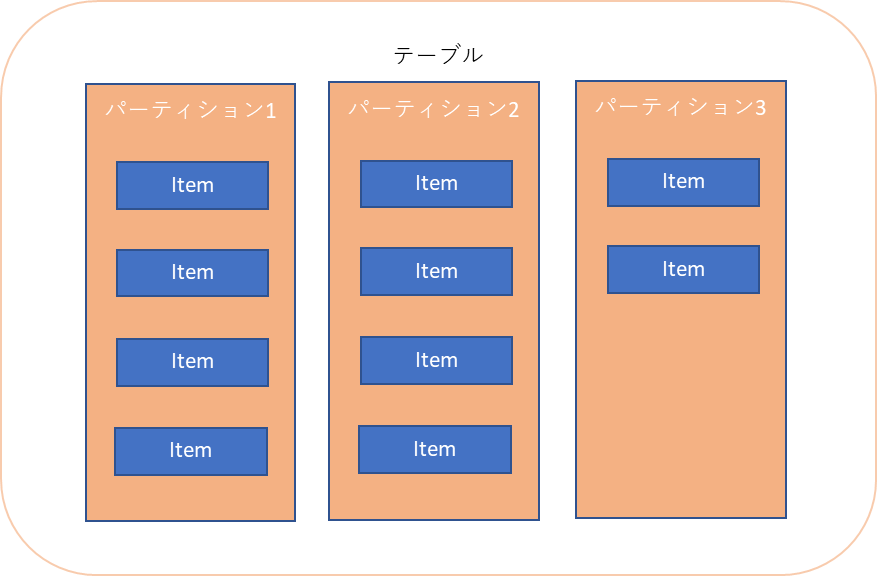
データ構造
パーティションキーとソートキーというレコードが一意になるキー項目があり、その中に属性があります。
属性には項目を複数設定する事が出来、RDBと違う所はテーブルは正規化せずにあらゆる項目を入れておいて、GSI(Global Secondary Index)を使用して別の項目をキーにする事が可能です。
基本的にパーティションキーとソートキーによる検索処理を実施します。他の項目で検索をする事も可能ですが、処理速度が落ちるみたいです。
データイメージ
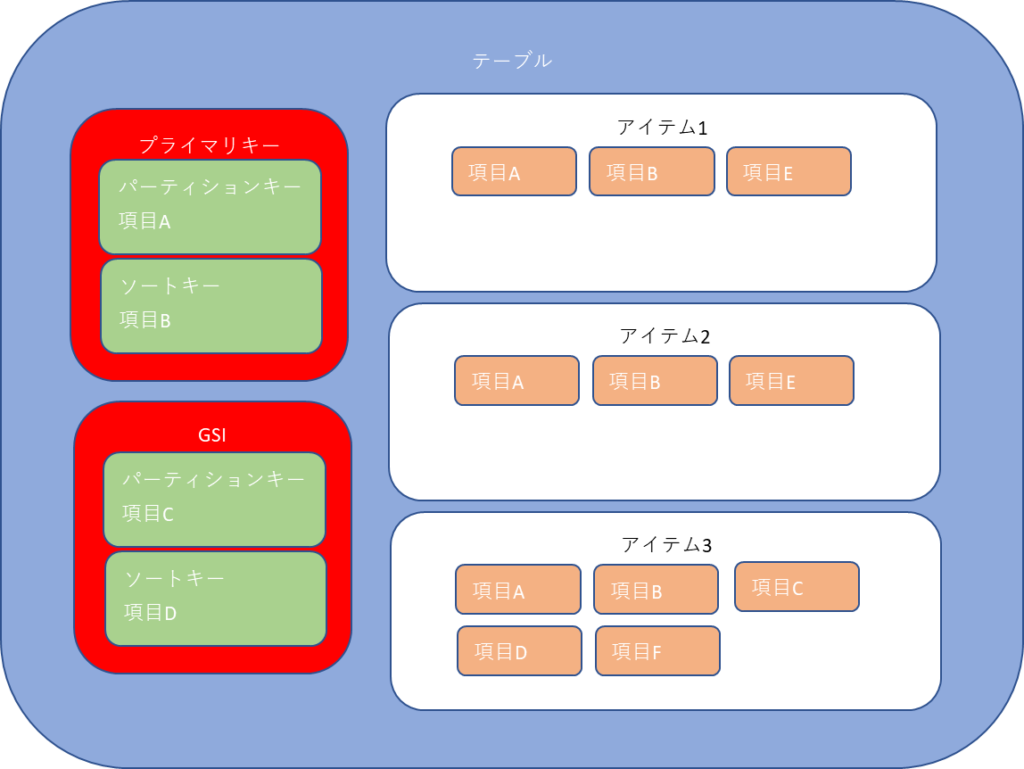
データ例
テーブル例
| ユーザID(PK) | ゲームID(SK) | 属性 |
| 001 | 0 | キャリアスタート日付:2022/01/01 |
| 002 | 0 | キャリアスタート日付:2021/01/01 |
| 001 | 1 | スコア日付:2022/01/02 スコア:1200 |
| 001 | 2 | スコア日付:2022/02/02 スコア:5000 |
| 002 | 1 | スコア日付:2022/03/01 スコア:20000 |
GIS例
PKとSKを別の項目にしたい時にGSIを使用(今回はSKは無しにしています)
通常テーブルの属性のキャリアスタート日付がPKになり、ユーザIDが属性になっています。
| キャリアスタート日付(PK) | 属性 |
| 2022/01/01 | ユーザID:001 |
| 2021/01/01 | ユーザID:002 |
使用例
- システム使用の行動履歴データ
- 位置情報データ
- ゲームの行動履歴データ
- IOTからの蓄積データ
- ゲーム対戦マッチングデータ
Redshift
概要
データの抽出・集約に特化したBIデータ分析用のデータベースです。
読み込むデータ構造を考慮し、その形式に加工してからデータを挿入します。
データ抽出・集計が速いが、更新・トランザクションは遅いです。
データ解析用ツールはAWSのサービスとしても提供されています。
アーキテクチャ
データ量とクエリ内容に応じて分散処理を効率的に実施してくれます。
RDSと同じ列指向のデータベースで大容量のデータをパーティションニングして複数ディスクから読み込むようにI/Oを効率化しています。
ワークロードという機能を使用しクエリ実行の優先順位の設定や機械学習によりクエリ実行順序を効率的に実行す機能なども存在します。
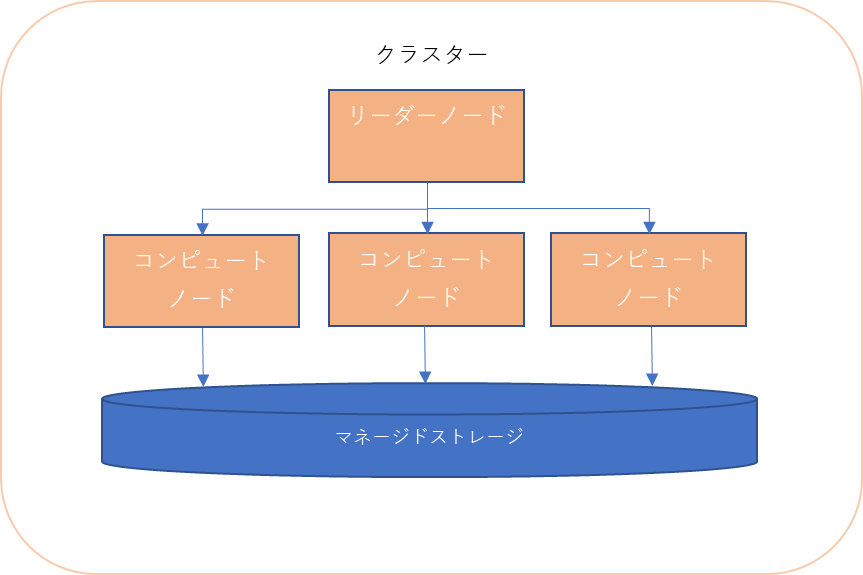
構成はクラスターというグループの単位で複数ノードによってデータ処理をする構成です。
リーダーノードはクエリのエンドポイントでSQLコード生成や実行を行います。
コンピュートノードはマネージドストレージに並列実行を行います。
ノードを追加するとコンピュートノードが追加する事でパフォーマンスが向上されます。
同時実行スケーリングでは一時的なクラスターが追加されパフォーマンスが向上されます。
使用例
- 業務系データのBI利用
- 会計データのBI利用
- 販売管理データのBI利用
ElastiCache
概要
インメモリキャッシュにデータを保管し、シンプルなオペレーションを分散して高速実行するデータベースです。
インメモリキャッシュとは、特定のデータを一時的に保管しておくデータベース構造をメモリ上に持たせる仕組みです。
アーキテクチャ
memcachedとredisという2種類のエンジンを選択して使用する事が可能です。
redisのアーキテクチャを下に定義します。
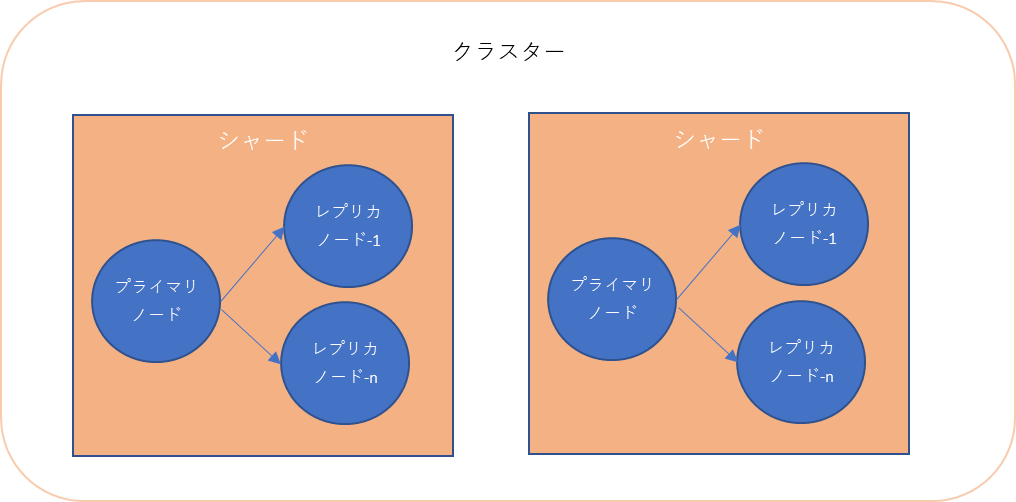
構成はクラスターというグループに複数のシャードで構成されています。
※クラスターモード無効の場合はシャード1個
複数のシャードを持つ事でシャーディングが可能になります。
1シャードに対するノード数はプライマリ1個、レプリカ最大5個持つことが出来ます。
ノードはElastiCacheの最小単位で、保存領域を持ちます。
データ構造
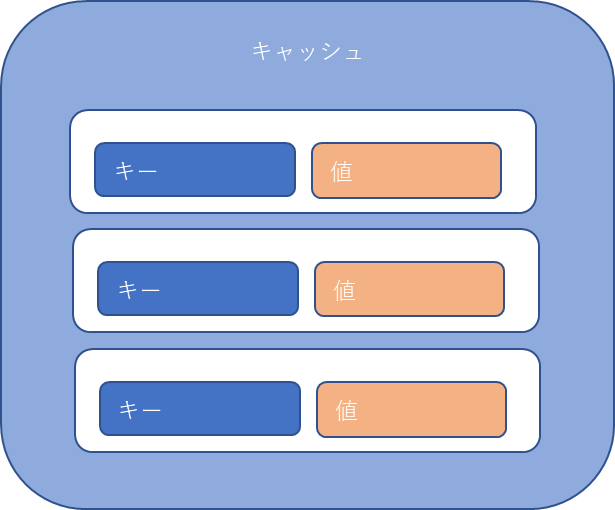
テーブルやリレーションなどは無くキーに対して値を設定します。
データイメージ
データ例
| キー | 値 |
| 001_1 | 日付:2022/01/01,スコア:10000,クリア人数: |
| 001_2 | 日付:2022/01/02,スコア:5000,クリア人数:2 |
| 002_1 | 日付:2022/01/01,スコア:20000,クリア人数: |
使用例
- セッション管理
- ゲームにおけるユーザ同士のデータ同期処理
- ソーシャルゲームなどのデータ処理
- マスタデータの保管
- 画像データの高速表示
- IOTデータ処理
続けてお読みください
この記事をシェアする
お電話でのお問い合わせ
03-5820-1777(平日10:00〜18:00)