- 03-5820-1777平日10:00〜18:00
- お問い合わせ
コラム
Lambdaで外部ライブラリを使用(レイヤー使用)
Lambdaレイヤーとは
LambdaレイヤーとはLambda関数で使用できるライブラリとその他の依存関係をパッケージ化し、Lambda関数間で共有可能にする機能です。
この機能を使用する事によりLambda関数のアーカイブサイズを小さくする事も可能になります。
レイヤーには、ライブラリ、 カスタムランタイム 、データ、設定ファイルなどを含める事が出来ます。
今回やる事
PDF操作用の外部ライブラリをレイヤーにデプロイし、Lambda関数から呼ぶ処理を作成し正常に動作するか確認していきます。言語はpythonを使用します。
下記のようなPDFテンプレートを用意して、それに値を入力したファイルデータを取得する機能を作成します。
テンプレート

完成イメージは下記です。
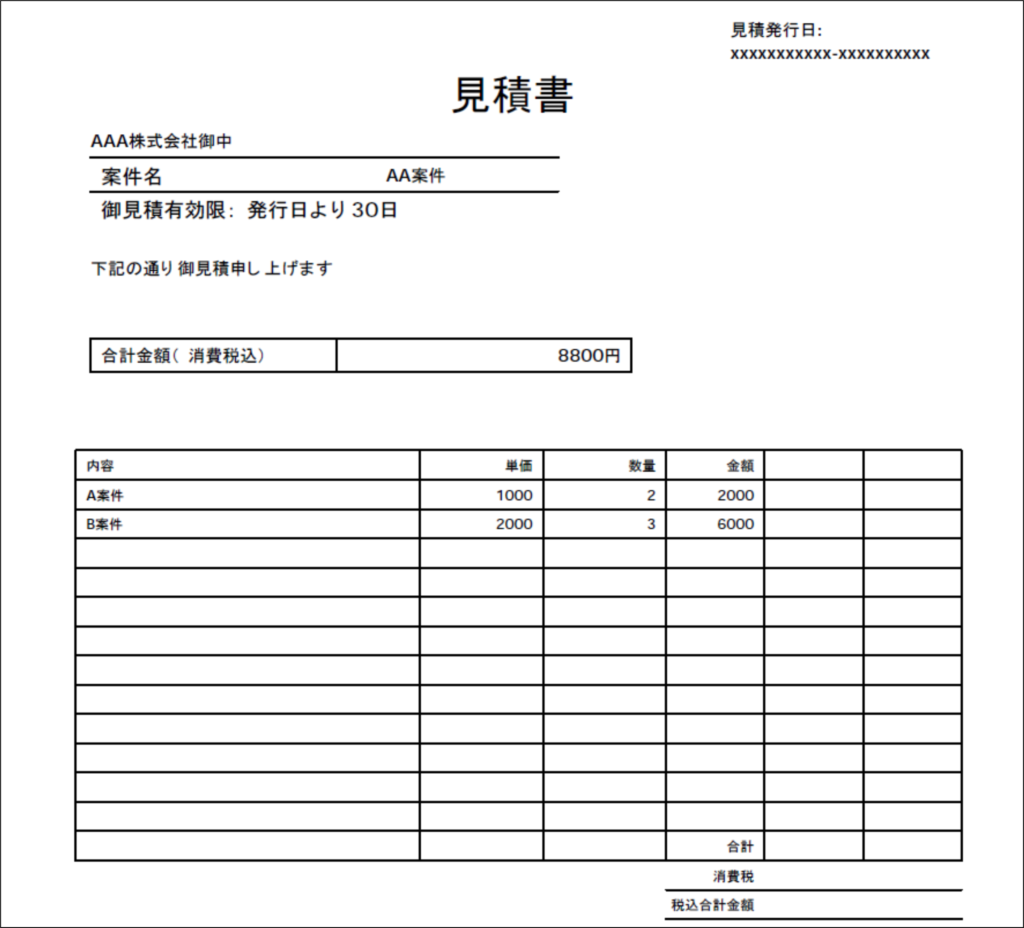
又、エラーになるパターンも幾つか紹介していきます。
レイヤ作成
1.PDFライブラリをZIP形式で纏める
・「python」というディレクトリを作成し、PDF用ライブラリをインストール(pythonの場合はこの名前でないと上手く動作しませんでした)
Windows用コマンド
pip install reportlab -t ./python --no-user
pip install pypdf2 -t ./python --no-userLinux用コマンド
pip install reportlab -t ./python
pip install pypdf2 -t ./python・「python」ディレクトリをZIPファイルに纏める
WindowsはExploer上でディレクトリを右クリックし「送る」のメニューの「圧縮(Zip形式)フォルダー」でZIP化する事が出来ます。
Linuxでは以下のコマンドを使用
zip -r layer.zip pythonZIPのファイル名はなんでも良いみたいです。
2.レイヤー作成、ZIPアップロード
メニューのレイヤーを選択し、右側のレイヤー作成ボタンを押下します。
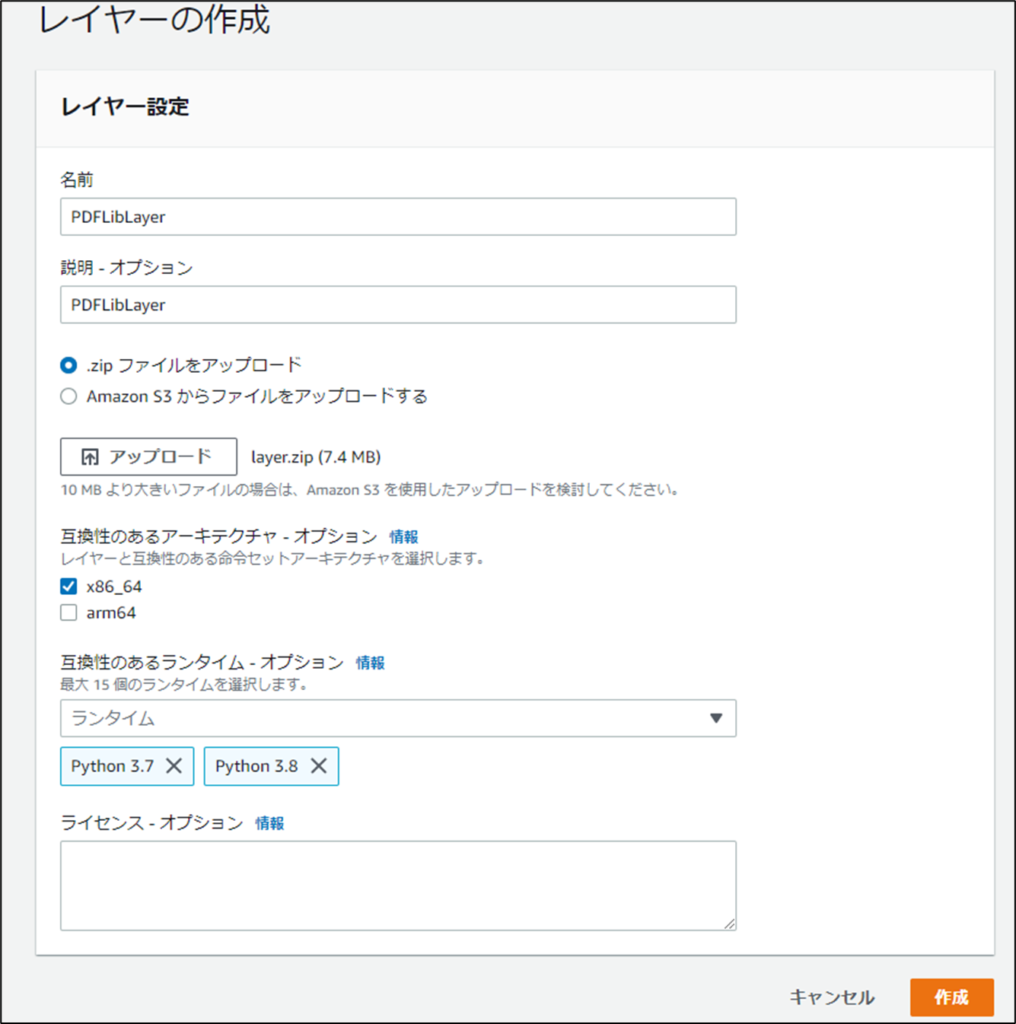
次の情報を入力し作成を押下します。
- 名前 :今回はPDFLibLayerという名前を入力
- 説明 :今回は名前と同じ値を入力
- Zipファイル :先ほど作成したZIPファイルをアップロード
- 互換性のあるアーキテクチャ :今回は「x86_64」を使用
- 互換性のあるランタイム :「Python3.7」と「Python3.8」を選択
- ライセンスオプション :今回は必要ないので未入力
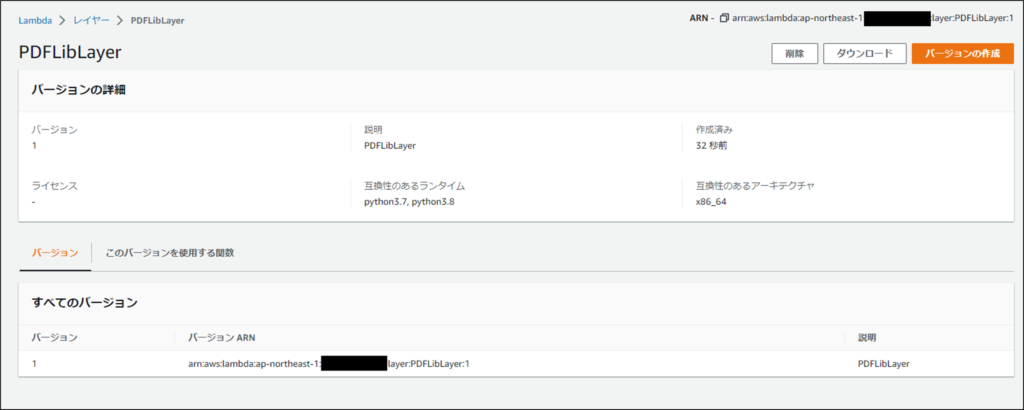
作成後画面、バージョンを上げていく事なども可能です。
Lambda関数作成
lambda関数のコードはDockerコンテナ上でLambdaを動作(PDFファイル作成、ダウンロード機能)の記事と同様のものを使用します。次の3つのファイルを用意します。
1.PDFファイル取得プログラム作成
- createpyf.py :テンプレートを読み込んで値を入力した新たなPDFファイルを作成する
- lambda_function.py :Lambda関数として起動するメインファイル
- template.pdf :PDF作成の際のテンプレートとして利用する
createpyf.py
from PyPDF2 import PdfFileWriter, PdfFileReader
from reportlab.pdfgen import canvas
from reportlab.lib.pagesizes import A4, portrait
from reportlab.lib.units import inch, mm, cm
from reportlab.pdfbase import pdfmetrics
from reportlab.pdfbase.ttfonts import TTFont
from reportlab.pdfbase.cidfonts import UnicodeCIDFont
from reportlab.platypus import Table, TableStyle
from reportlab.lib import colors
class ReportlabView():
def _create_pdf(self, output_file, template_file):
# ファイルの指定
tmp_file = '/tmp/tmp.pdf' # 一時ファイル
# Canvasを作成
w, h = portrait(A4)
cv = canvas.Canvas(tmp_file, pagesize=(w, h))
# フォントを登録しCanvasに設定
font_size = 10
font_name = 'HeiseiKakuGo-W5'
pdfmetrics.registerFont(UnicodeCIDFont(font_name))
cv.setFont(font_name, font_size)
# 文字列を描画
cv.drawString(
20 * mm,
264 * mm,
"AAA株式会社御中"
)
cv.drawString(
80 * mm,
257 * mm,
"AA案件"
)
data = [
["8800円"], #合計金額
]
table = Table(data, colWidths=(60 * mm), rowHeights=(7 * mm))
table.setStyle(
TableStyle(
[
("FONT", (0, 0), (-1, -1), font_name, 10),
# ("BOX", (0, 0), (-1, -1), 1, colors.red),
# ("INNERGRID", (0, 0), (-1, -1), 1, colors.black),
("VALIGN", (0, 0), (-1, -1), "MIDDLE"),
("ALIGN", (0, 0), (-1, -1), "RIGHT"),
]
)
)
table.wrapOn(
cv,
70 * mm,
218 * mm,
)
table.drawOn(
cv,
70 * mm,
218 * mm,
)
data = []
data.append(["A案件", "1000", "2", "2000", "", ""])
data.append(["B案件", "2000", "3", "6000", "", ""])
table = Table(
data,
colWidths=(70 * mm, 25 * mm, 25 * mm, 20 * mm, 20 * mm, 20 * mm),
rowHeights=6 * mm,
)
table.setStyle(
TableStyle(
[
("FONT", (0, 0), (-1, -1), font_name, 8),
("VALIGN", (0, 0), (-1, -1), "MIDDLE"),
("ALIGN", (1, 0), (-1, -1), "RIGHT"),
]
)
)
table.wrapOn(cv, 17 * mm, 184 * mm)
table.drawOn(cv, 17 * mm, 184 * mm)
# 一時ファイルに保存
cv.showPage()
cv.save()
# テンプレートとなるPDFを読む
template_pdf = PdfFileReader(template_file)
template_page = template_pdf.getPage(0)
# 一時ファイルを読んでマージする
tmp_pdf = PdfFileReader(tmp_file)
template_page.mergePage(tmp_pdf.getPage(0))
# 出力用PDFを用意し書き込む
output = PdfFileWriter()
output.addPage(template_page)
with open(output_file, "wb") as fp:
output.write(fp)
lambda_function.py
import json
import base64
import createpdf
import os
def lambda_handler(event, context):
# PDF作成クラスインスタンス取得
ss = createpdf.ReportlabView()
# PDF作成処理依頼
ss._create_pdf( '/tmp/sample.pdf', 'template.pdf' )
# 作成されたファイルを読み込み、Base64に変換して返す
with open("/tmp/sample.pdf", "rb") as file_data:
text = file_data.read()
text = base64.b64encode( text ).decode('utf-8')
# 返す値はJSON形式の文字列で返す。ファイルダウンロードする際は以下の様な記述にする。
return {
"statusCode": 200,
"headers": {
'Content-Length': len(text),
'Content-Type': 'application/pdf',
'Content-disposition': 'attachment;filename=output.pdf'
},
"isBase64Encoded": True,
"body": text
}2.用意したファイルをZIP形式に纏める
上記で用意したファイルをZIP形式に纏めます。ディレクトリは必要ないです。
3.Lambda関数作成、ZIPアップロード、レイヤー設定
一から作成を選択、関数名は「CreatePDFUseLayer」にします。
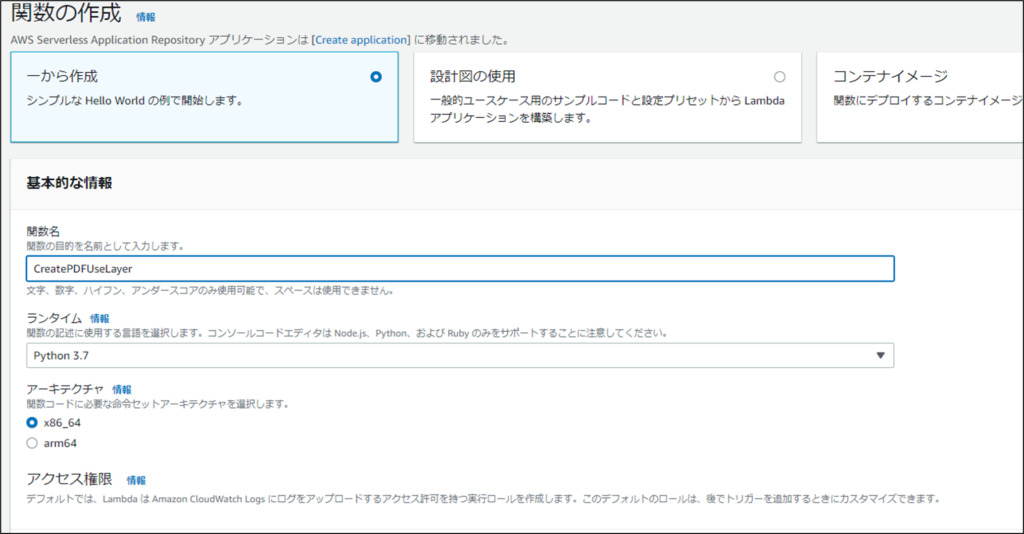
作成した関数に先ほど作成したZIPファイルをアップロードします。
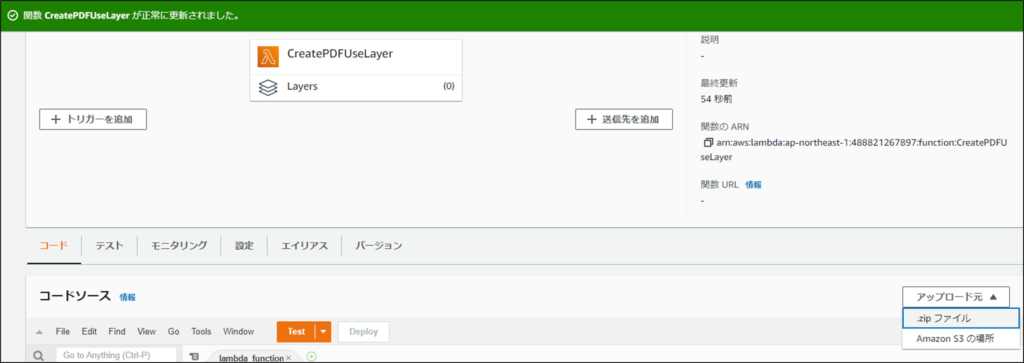
アップロードが終了しコードタブを選択するとZIPファイルの内容で更新されている事が分かります。
4.レイヤー設定
関数の作成が終了したら次はレイヤーの設定をしていきます。
作成した関数画面の一番下にレイヤー情報があるのでそこからレイヤーを追加していきます。
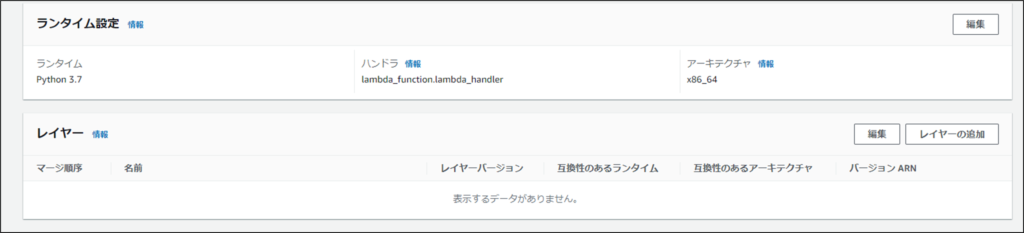
レイヤー追加ボタンを押下するとレイヤー追加画面に遷移します。
カスタムレイヤーを選択し、先ほど作成したレイヤーを選択して追加するとそのレイヤーのライブラリが使用できるようになります。
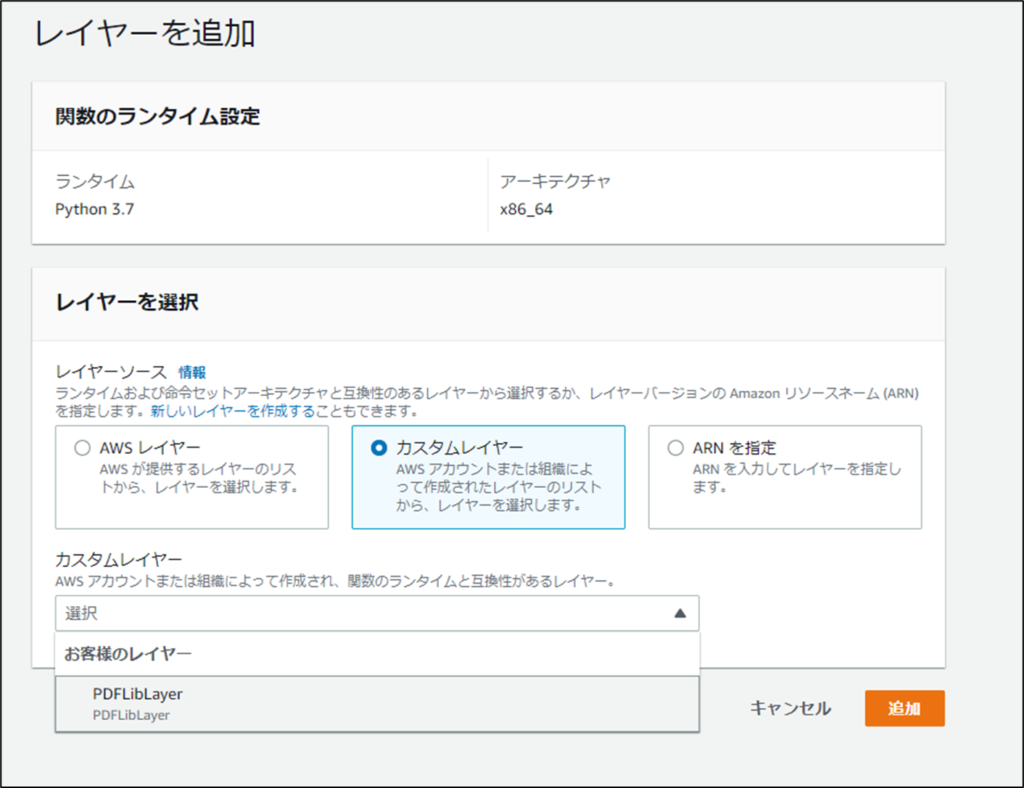
以上で設定が完了です。次は動作確認をしていきます。
動作確認
Lambda単体でテスト
まずLambda単体でテストをてみます。
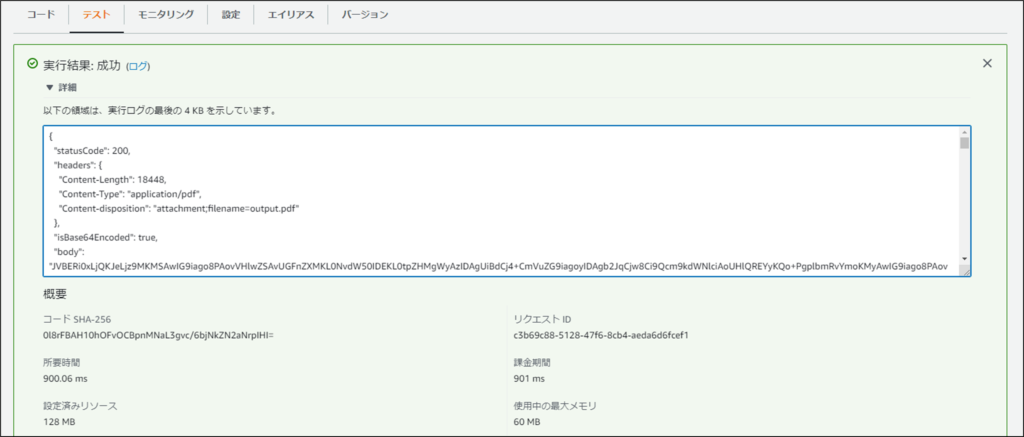
以上の様な結果が返ってきたら正常に動作しています。
作成したPDFファイルの内容はbody部分に値があります。これをファイルとしてダウンロードするにはApi Gatewayを使用する必要があります。
次はApi GatewayでLambda関数にアクセスして検証してみたいと思います。
Api Gatewayでのテスト
これもDockerコンテナ上でLambdaを動作(PDFファイル作成、ダウンロード機能)でのテストと同様の事をします。
Lambda関数画面でトリガー追加を押下します。
API Gatewayを選択します。
IntentはCreate a new APIを選択します。
API TypeはHTTP APIを選択します。
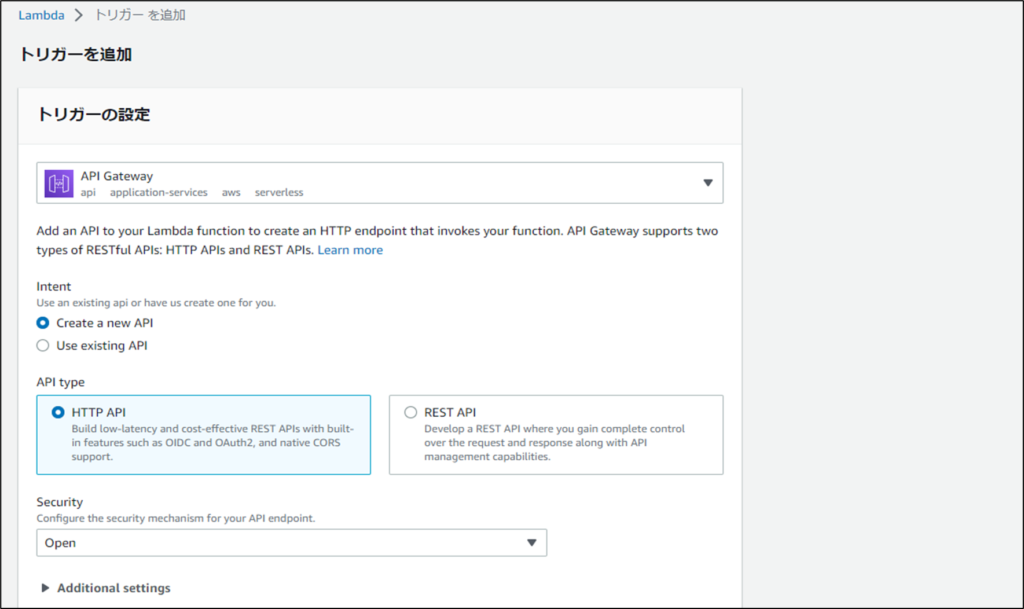
追加ボタンを押下するとトリガーにAPI Gatewayが作成されます。
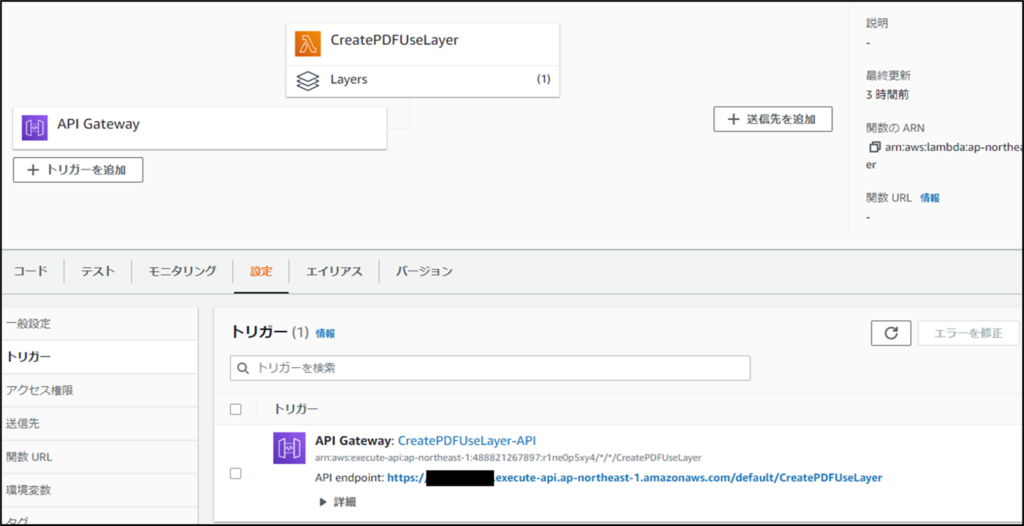
API Gatewayを押下すると下記の画面が出てきます。
API endpointに記述してあるURLにアクセスします。
output.pdfファイルがダウンロードされたら、正常に動作せてる事が確認できます。
エラーになるケース
エラーになるケースを幾つか紹介します。
レイヤーにアップロードするZIPファイル内のディレクトリ名が正しくない場合
pythonを使用している場合、ライブラリ等のファイルが「python」というディレクトリ配下にある必要があります。
そうでない場合は以下のエラーが出力されます。
{
"errorMessage": "Unable to import module 'lambda_function': No module named 'PyPDF2'",
"errorType": "Runtime.ImportModuleError",
"stackTrace": []
}
他の言語の場合はどうなのかは確認してませんので、いずれ確認してみたいと思います。
Pythonのバージョンに相違がある場合
Pythonのバージョンが3.10でインストールしたパッケージをレイヤーにアップロードし、Lambda関数のPython3.7や3.8で実行した場合、以下のエラーが出ました。
{
"errorMessage": "Unable to import module 'lambda_function': No module named 'typing_extensions'",
"errorType": "Runtime.ImportModuleError",
"stackTrace": []
}続けてお読みください
この記事をシェアする
お電話でのお問い合わせ
03-5820-1777(平日10:00〜18:00)